Kubernetes集群在跑几天之后总会有一两个Etcd节点的系统负载特别高,甚至高达27,ssh进去半天才有响应,之前图省事每当负载高到离谱的时候我就reboot又能坚持几天。
然而这个问题始终反复困扰着我,还是得花点时间彻底解决一下这个系统负载高的问题,通过top命令我得知CPU资源被百分之百占用的程序是Etcd。
这有点奇怪,Kubernetes用Etcd来存储它的一些配置信息,以及ConfigMap等。我的集群目前只有20个节点,所有的Pods加一起也就250个左右,按理说这么点数据量对于三个节点构成高可用集群的Etcd来说不应该存在瓶颈的。
只能看一下Etcd的logs日志,发现所有Etcd占用CPU高的节点日志大量存在类似以下Warn信息
2020-05-19 18:34:05.173701 W | etcdserver: read-only range request "key:\"/registry/health\" " with result "range_response_count:0 size:7" took too long (140.510254ms) to execute
2020-05-19 18:34:05.173821 W | etcdserver: read-only range request "key:\"/registry/masterleases/\" range_end:\"/registry/masterleases0\" " with result "range_response_count:3 size:414" took too long (279.440258ms) to execute
在看一下有没有duration相关
$ kubectl logs -n kube-system etcd-node5 | grep duration
2020-05-15 02:39:31.581538 W | wal: sync duration of 1.36675899s, expected less than 1s
2020-05-17 03:50:07.355590 W | wal: sync duration of 1.410356061s, expected less than 1s
2020-05-18 21:45:09.729681 W | wal: sync duration of 1.045373576s, expected less than 1s
2020-05-19 02:20:07.252321 W | wal: sync duration of 1.065346865s, expected less than 1s
2020-05-19 17:04:06.569290 W | wal: sync duration of 1.017309852s, expected less than 1s
$ kubectl logs -n kube-system etcd-node4 | grep duration
2020-05-17 12:09:38.175434 W | wal: sync duration of 1.836969728s, expected less than 1s
$ kubectl logs -n kube-system etcd-node6 | grep duration
2020-05-15 06:12:27.034174 W | wal: sync duration of 1.659465985s, expected less than 1s
2020-05-15 22:05:39.893569 W | wal: sync duration of 1.788391843s, expected less than 1s
2020-05-16 00:44:46.210859 W | wal: sync duration of 1.145156303s, expected less than 1s
2020-05-19 08:49:33.054751 W | wal: sync duration of 1.006146785s, expected less than 1s
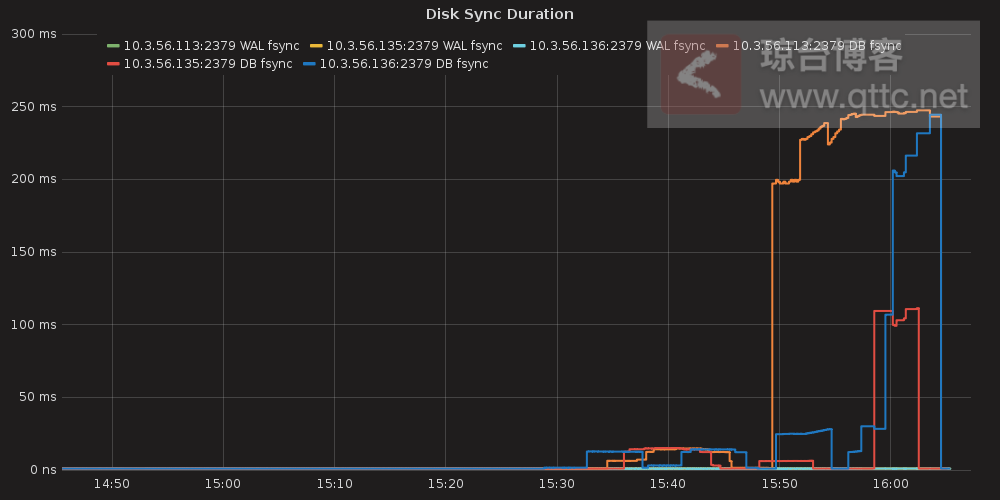
这些Warn日志里都包含一个重要关键字took too long,网上查一下得知通常是磁盘写入速度慢导致的,看一下指标
$ curl http://127.0.0.1:2381/metrics | grep etcd_disk_wal_fsync_duration
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.001"} 850539
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.002"} 1.506213e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.004"} 1.821136e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.008"} 1.864528e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.016"} 1.870589e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.032"} 1.872096e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.064"} 1.872617e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.128"} 1.872795e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.256"} 1.872858e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.512"} 1.872882e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="1.024"} 1.872895e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="2.048"} 1.872899e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="4.096"} 1.872899e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="8.192"} 1.872899e+06
etcd_disk_wal_fsync_duration_seconds_bucket{le="+Inf"} 1.872899e+06
etcd_disk_wal_fsync_duration_seconds_sum 2822.5543681490526
etcd_disk_wal_fsync_duration_seconds_count 1.872899e+06
我的Kubernetes集群都是构建在云平台提供的ECS机器上的,在创建ECS实例时有一个磁盘选项,我选的是I/O最差的普通磁盘,网上都推荐该用SSD磁盘做为Etcd数据盘。
Etcd提供了Prometheus直接能读取的metrics,通过它也可以很直观的看到Disk Sync Duration相关的趋势,更容易判断你的磁盘写入速度与实际差多少了,通常绝大多数情况下都推荐Etcd的数据盘使用SSD等相关告诉读写的磁盘,避免I/O成为它的瓶颈。
